Cancer Genomics: Using Big Data to Advance Breast Cancer Risk Prediction
Over the past decade, the prospect of transforming cancer care to the next level went from being bleak to bright, thanks to our ever-expanding knowledge of cancer genomics and the technologies that make such understanding possible.
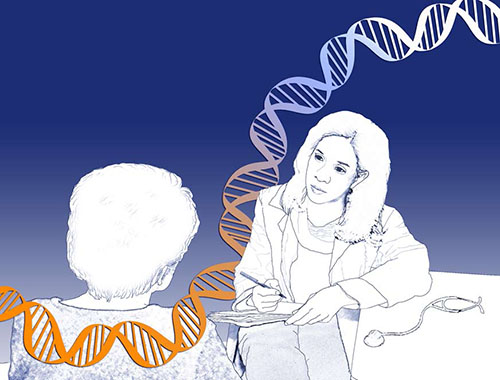
The utility of genomic sequencing in developing new cancer therapies is far-reaching, and its applicability in predicting cancer susceptibility and in cancer prevention is starting to emerge. Image by Jane Ades, NHGRI, at www.genome.gov.
Genomic sequencing is continuously changing the way we understand cancer. We have come to a point where the challenge is not so much how to generate large amounts of data, but how to harness the enormous amounts of genomic data churned out by ever-advancing technologies so that they translate into meaningful cancer prevention and treatment strategies.
“As we begin to identify more and more genetic alterations in a single tumor, we will need to use new ways to analyze our data,” said AACR President Carlos L. Arteaga, MD, in the AACR Cancer Progress Report 2014. “I think that the power of computational biology, which allows us to analyze many, many genetic alterations together, will revolutionize this area of cancer research.”
The application of genomic sequencing in developing new cancer therapies is far-reaching. Knowledge of genetic alterations in a person’s tumor is the driving force behind targeted therapies. While the utility of genomic sequencing in enhancing cancer therapies is quite evident from the wide array of revolutionary new treatment options, its applicability in predicting cancer susceptibility and in cancer prevention is starting to emerge.
A paper published in the AACR journal Cancer Epidemiology, Biomarkers & Prevention today is a useful example of how big data could be exploited by computational biologists to find innovative ways to improve cancer care.
In this study, a team of computational biologists from Stanford Cancer Institute addressed the uncertainty surrounding the utility of genome-wide sequencing in developing personalized breast cancer prevention strategies. The researchers used known breast cancer susceptibility variants, including those in BRCA1, BRCA2, TP53, PTEN, and 82 others, to develop a genomic risk score and assess an individual’s risk for developing breast cancer.

Alice S. Whittemore, PhD, is lead author on a new study that suggests it is feasible to use genomic sequencing to identify women who would benefit most from breast cancer screening practices.
With the computational model they developed, they found that the variance of the risk score based on the 86 known breast cancer susceptibility variants for women in the United States was five times higher than what was estimated in previous studies. The higher the variance, the greater our ability to identify an individual’s risk score, lead author Alice S. Whittemore, PhD, professor of epidemiology and biostatistics at Stanford, explained.
“As we keep identifying additional breast cancer variants that can further explain the difference between my risk versus yours, the variance of the genetic risk score in the population will increase, and the potential utility of genomic sequencing will grow,” said Weiva Sieh, MD, PhD, assistant professor and epidemiologist at Stanford, and first author on this study.
Leveraging big data to improve breast cancer risk prediction is, in fact, one of the goals of a brand new initiative by the National Institutes of Health (NIH).
On Oct. 9, the NIH announced its Big Data to Knowledge (BD2K) initiative in which it is investing nearly $32 million in 2014, with a projected total investment of nearly $656 million through 2020. According to the press release, this initiative will “develop new strategies to analyze and leverage the explosion of increasingly complex biomedical data sets, often referred to as big data.”
The ultimate goal of this initiative is to exploit the power of big data in improving human health. Some examples cited include an improved ability to predict who is at increased risk for breast cancer, heart attack, and other diseases and conditions, and better ways to treat and prevent them.
To achieve these goals, the initiative will develop innovative approaches to address the various aspects of big data science; coordinate the characterization of a variety of human cells and tissues that respond to cancer drugs and other factors; address the discovery, access, and citation of biomedical research data sets; and support the education and training of current and future generations of researchers who will specialize in data science fields.
This is clearly a very promising time for cancer research. Big initiatives to decipher big data are stepping stones to comprehensive cancer care that integrates cancer genomics into cancer prevention and treatment.
Cover image: DNA Double Helix from NHGRI